
Sentiment Analysis and text classification using python

Introduction
Natural language processing (NLP) is a subfield of linguistics, computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data.
Sentiment analysis is part of the Natural Language Processing (NLP) techniques that consists in extracting emotions related to some raw texts. This is usually used on social media posts and viewers reviews in order to automatically understand if some users are positive or negative and why.
The goal of this study how could leverage natural language processing and machine learning to accurately re-classify the posts to their respective subreddit and to show how sentiment analysis can be performed using python and creating a classification model that can distinguish which of two subreddits a post belongs to and get the most accuracy rate to predict the analysis.
About the Data
This dataset consists of a nearly 1000 subreddits viewer reviews (input text), title, subreddit details. for learning how to train Machine for sentiment analysis.
My data acquisition process involved using the requests library to loop through requests to pull data using Reddit’s API which was not pretty straightforward. I filtered those data through coding so that I can get the valuable data. To get posts from Star Wars, all I had to do was add .json to the end of the URL. Reddit only provides 25 posts per request and I wanted 1000 so I iterated through the process 10 times.
How this data will work?
The assumption for this problem is that a disgruntled, Reddit back-end developer went into every post and replaced the subreddit field with “(·̿̿Ĺ̯̿̿·̿ ̿)”. As a result, none of the subreddit links will populate with posts until the subreddit fields of each post are re-assigned.
We can use this data to analyze among two subreddits ; discover insights into viewer reviews and assist with machine learning models. We can also train our machine models for sentiment analysis and analyze distribution of viewer reviews in the datasets.
Here are some of the main libraries we will use:
NLTK: the most famous python module for NLP techniques
SK-learn: the most used python machine learning library
We will use here two main sub reddits reviews data. Each observation consists in one viewer review for one subreddit. Each viewer review is composed of a textual review and with title.
Reddit 1: Star Wars
Reddit 2: Star Trek
First, I manually created a binary column for r/Star War or r/Star Trek and then using EDA, topic modeling, and sentiment analysis identified patterns of reviews across the datasets.
We first try to find out the how many people or viewers are giving review in which subreddits more.
For each textual review, we want to predict if it corresponds to a good review (the viewers is giving positive) or to a bad one (the viewers is giving negative)).
I considered 0-1 polarity range are positive review
Lesser than 0 polarity is negative review
The challenge here is to be able to predict this information using only the raw textual data from the review. Let’s get it started!
Load data
First try to filter out the subreddits to get the amounts of good self text.
We first start by loading the raw data. Then merged the each textual reviews are from both the subreddits. We group them together in order to start with only raw text data and no other information. The data sets are look like below:

1087 rows × 3 columns
After binarize the data sets are look like
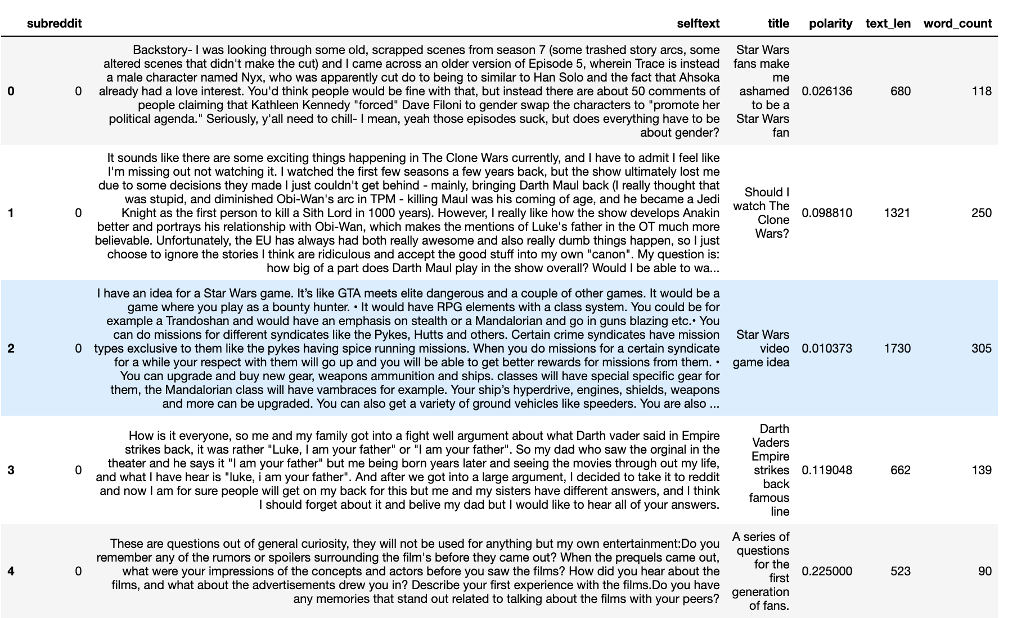
Initial dataset
Sample data
We sample the data in order to speed up computations.
Clean data
The next step consists in cleaning the text data with various operations:
To clean textual data, we call our custom ‘clean text’ function that performs several transformations:
- lower the text
- tokenize the text (split the text into words) and remove the punctuation
- remove useless words that contain numbers
- remove useless stop words like ‘the’, ‘a’ ,’this’ etc.
- Part-Of-Speech (POS) tagging: assign a tag to every word to define if it corresponds to a noun, a verb etc. using the WordNet lexical database
- lemmatize the text: transform every word into their root form (e.g. characters -> character, knew -> know)
Below top 20 self text after and before removing stop words:
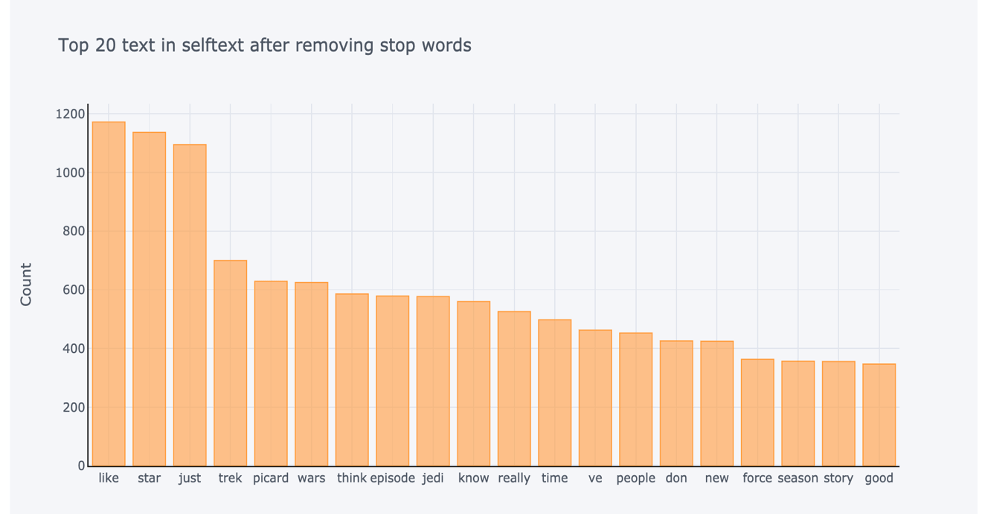
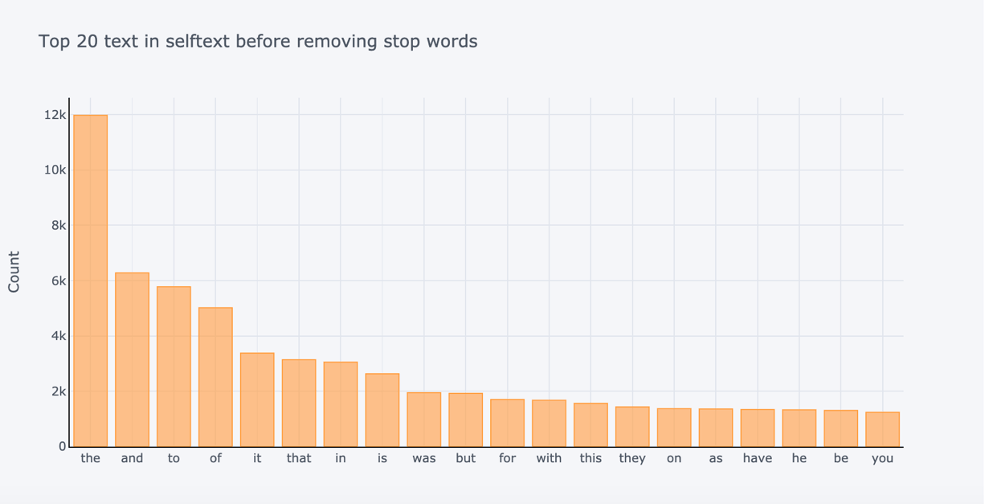
Now that we have cleaned our data, we can do some feature engineering for our modelization part.
Feature engineering
Exploratory Data Analysis
With EDA alone, we first start with sentiment analysis features because we can guess that viewers reviews are highly linked to how they felt about r/Star Wars and r/Star Trek. We use NLTK module designed for sentiment analysis. It also takes into account the context of the sentences to determine the sentiment scores. For each text, I calculated following values:(Codes below)
https://github.com/upad0412/reddit_post_classification
- polarity
- Text Length
- Word Count
Next, we add some simple metrics for every text:
- number of characters in the text
- number of words in the text
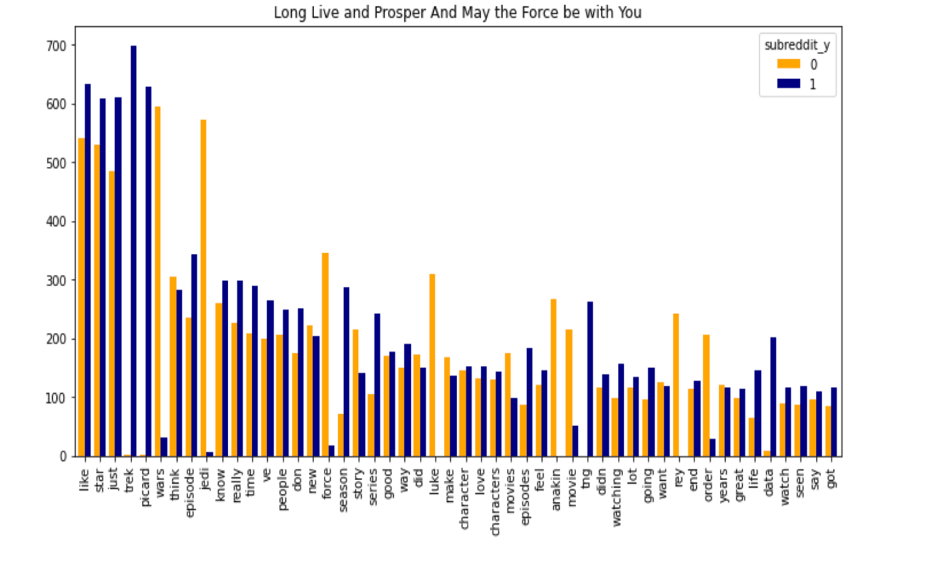
- Most frequent words in both the corpus
Word count ranges are not showing very high count level. Most of the words count in between 80-100.
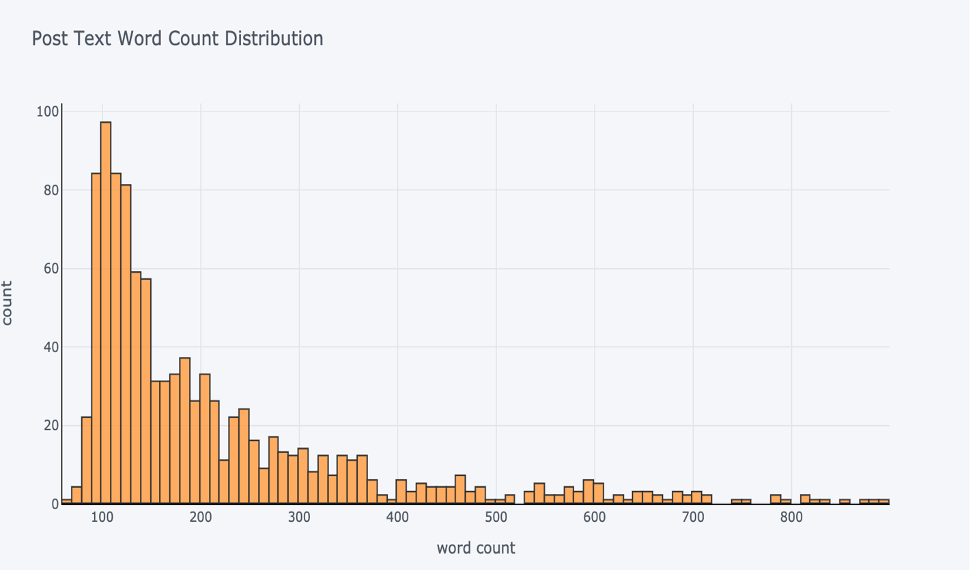
Next, we add TF-IDF columns for every word that appear in at least 10 different texts to filter some of them and reduce the size of the final output.
After exploration of various topic modeling techniques and vectorizers, I determined the strongest method for this problem was confusion matrix factorization with a TF-IDF vectorizer and lemmatization.
Word Cloud – top 100 words taking from both the clouds to visualize the words. Most of the words are indeed related to the opinions, their viewers words/characters, etc.
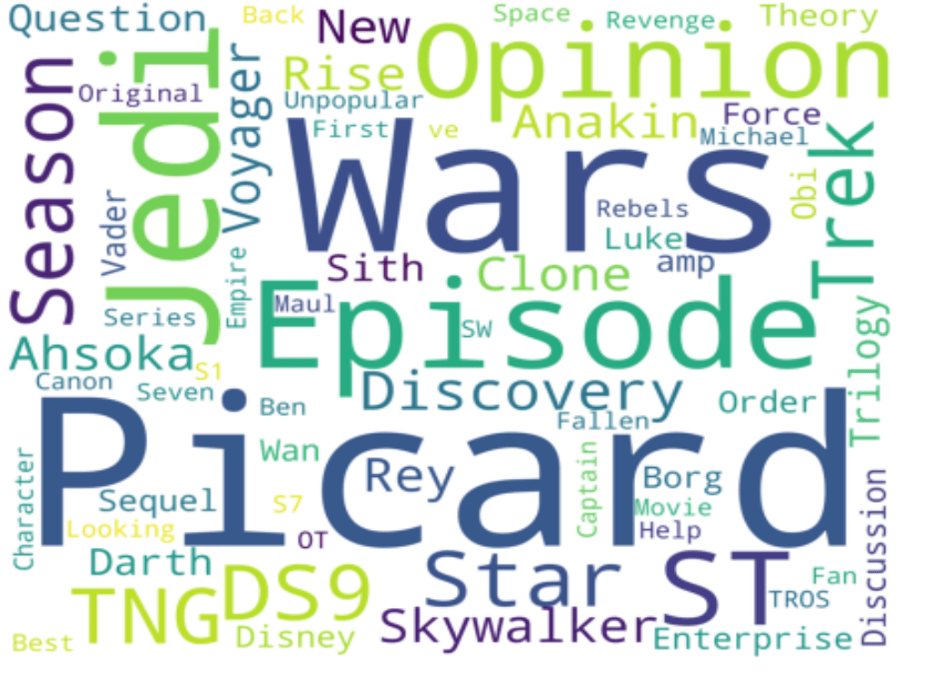
Word Cloud from the customer reviews
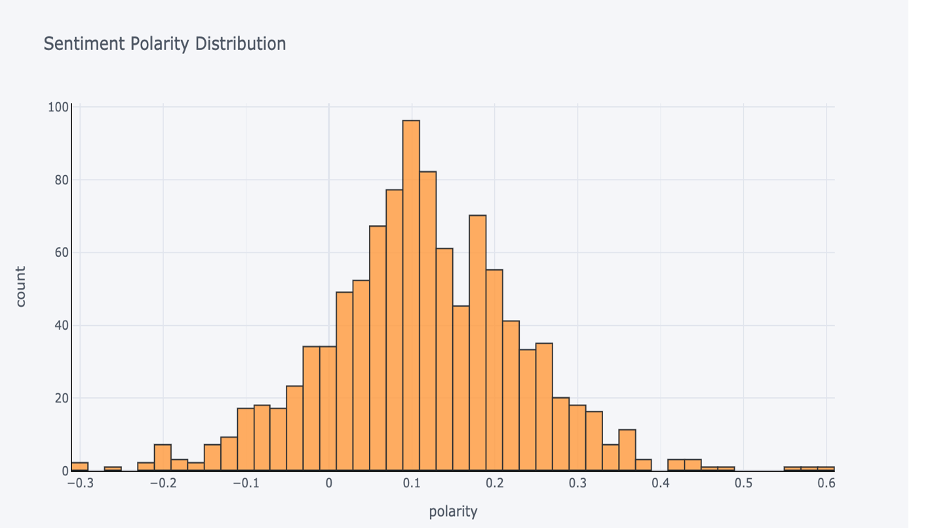
Sentiment distribution
The below graph shows the distribution of the review sentiments among good reviews and bad ones. We can see that good reviews are for most of them considered as very positive by Vader. On the contrary, bad reviews tend to have lower compound sentiment scores.
This shows us that previously computed sentiment features will be very important in our modelling part.
Most important features
The most important features are indeed the ones that come from the previous sentiment analysis. The vector representations of the texts also have a lot of importance in our training. Some words appear to have a fairly good importance as well.
I began my modeling process by creating my X and my y and splitting my data into training and test sets. I then moved on to my feature engineering process by instantiating two CountVectorizers for my Post Text features. CountVectorizer converts a collection of text documents (rows of text data) to a matrix of token counts. The hyperparameters (arguments) I passed through them were:
• stop_words=‘english’ (Post Text)
• ngram_range=(1, 2),
• min_df=.03 (Post Text)
• max_df=.95
• max_features=5_000
Stop words removes words that commonly appear in the English language. Min_df ignores terms that have a document frequency strictly lower than the given threshold.
An n-gram is just a string of n words in a row. For example, if you have a text document containing the words “I love my cat.” — setting the n-gram range to (1, 2) would produce: “I love | love my | my cat”. Having n-gram ranges can be helpful in providing the models with more context around the text I’m feeding it.
Modelling review
I assumed that setting of my Post Text feature, I gave it a higher n-gram range since post texts tends to be lengthier.
This resulted in 350 features which I fed into two variations of the models listed below. I built four functions to run each pair of models and Gridsearched over several hyperparameters to find the best ones to fit my final model with.
• Logistic Regression
• Multinomial Naive Bayes
The difference in variations was the fit_prior argument which decides whether to learn class prior probabilities or not. If false, a uniform prior will be used. One was set to True, while the other was set to False.
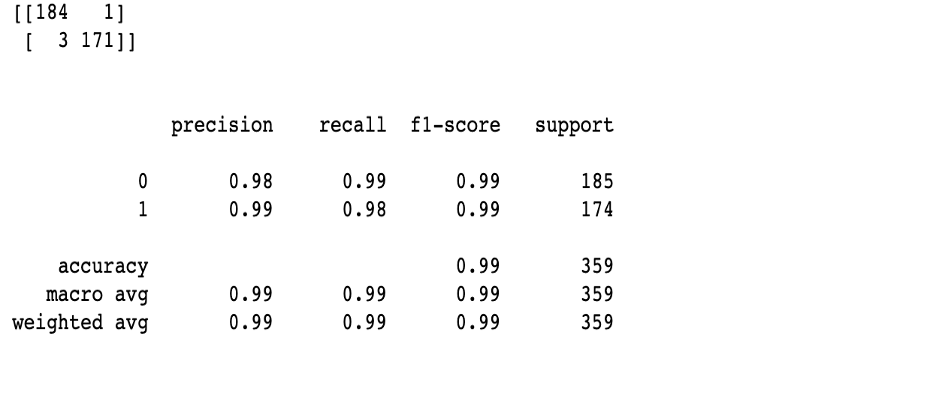
Such a classifier would have a precision of .99%, which corresponds to the proportion of positive observations. For every recall value the precision would stay the same, and this would lead us to an AP of 0.99. This means that our model has a good predictive power.
Among both the classification model my second Multinomial Naive Bayes model performed the best. With the best parameters being — alpha=0 and fit_prior=False. The accuracy score was 99.0% on training data and 98.0% on unseen data. This means our model is slightly and probably inconsequentially overfit. This also means that 99.0% of our posts will be accurately classified by our model.
Conclusion
Considering the small amount of data gathered and minimal amount of features used, the Multinomial Naive Bayes model was the most outstanding. It handled unseen data well and balanced the tradeoff between bias and variance the best among the eight models so I would use it to re-classify reddit posts. It is completely possible to use only raw text as input for making predictions. However if given more time and data to answer the problem I would recommend two things: 1) spending more time with current features (e.g. engineering a word length feature) and 2) exploring new features (e.g. upvotes or post title).
This kind of data can often come as a good complementary source in data science projects in order to extract more learning features and increase the predictive power of the models.
Here is the link to the original Jupyter notebook on Github:
